本帖最后由 yakeyun 于 2022-5-23 21:40 编辑
回复 30# 13545876873
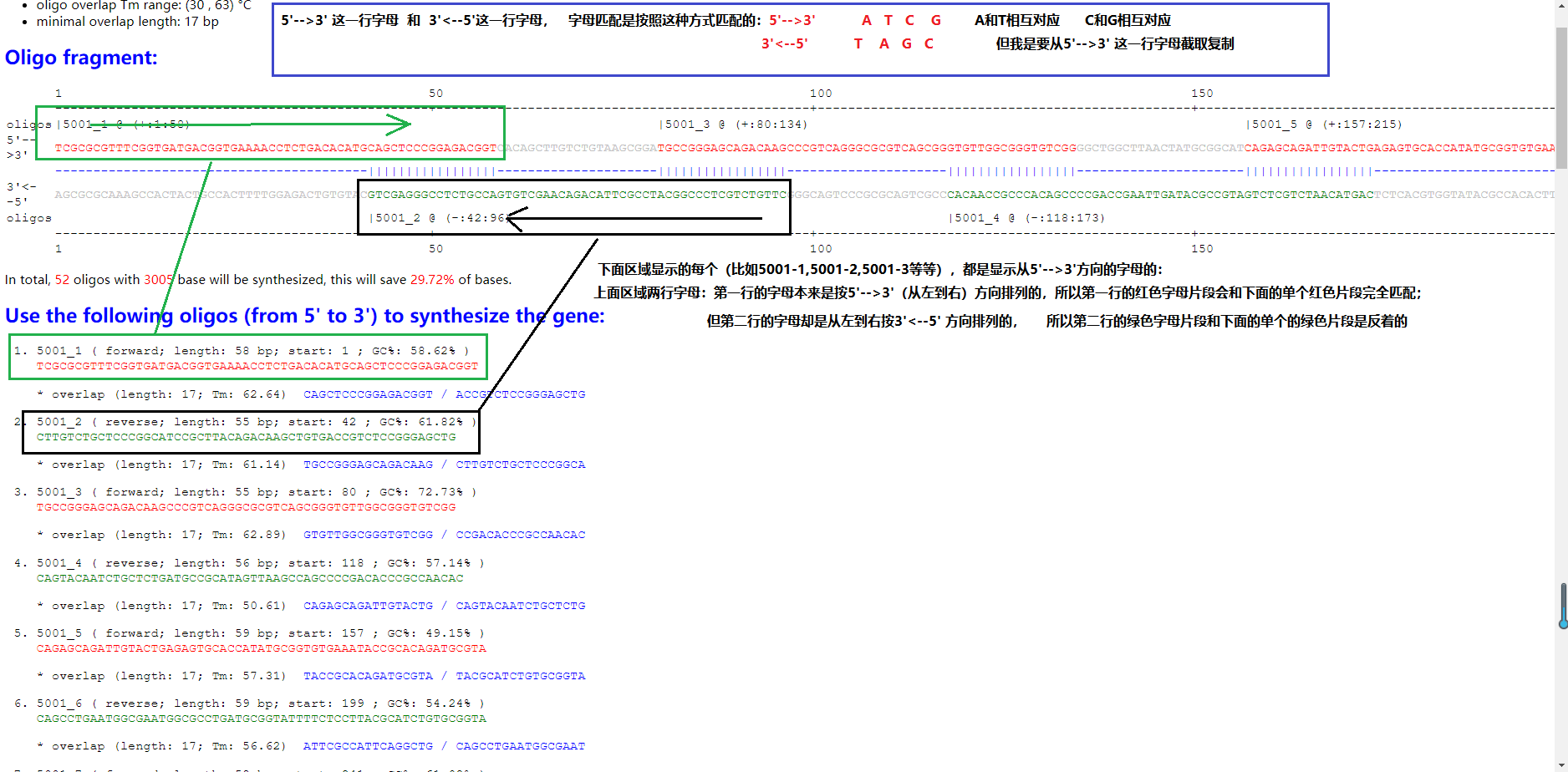
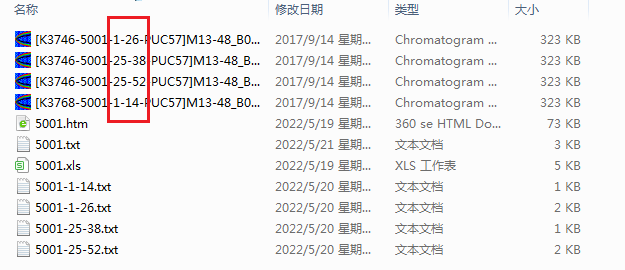
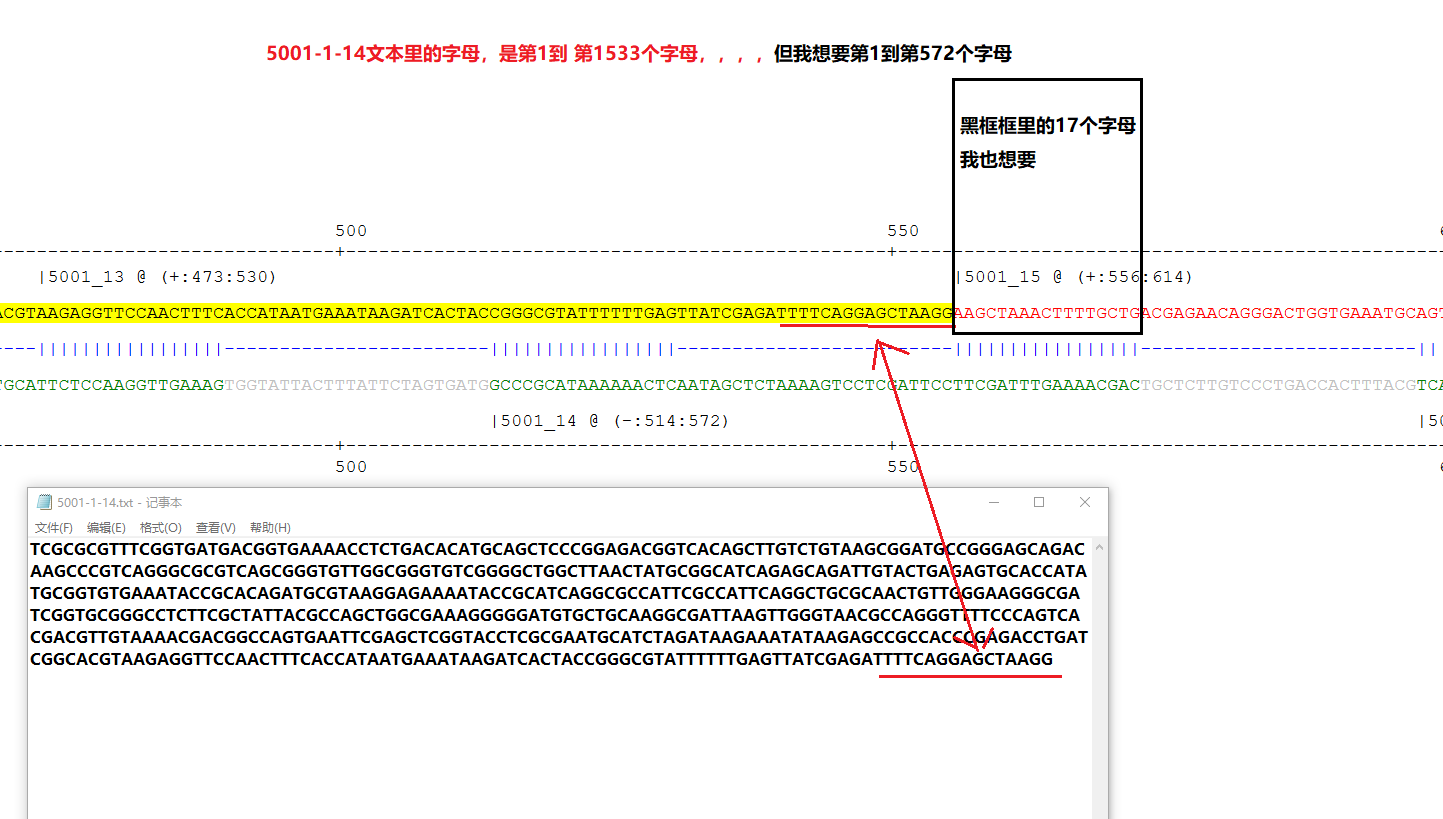
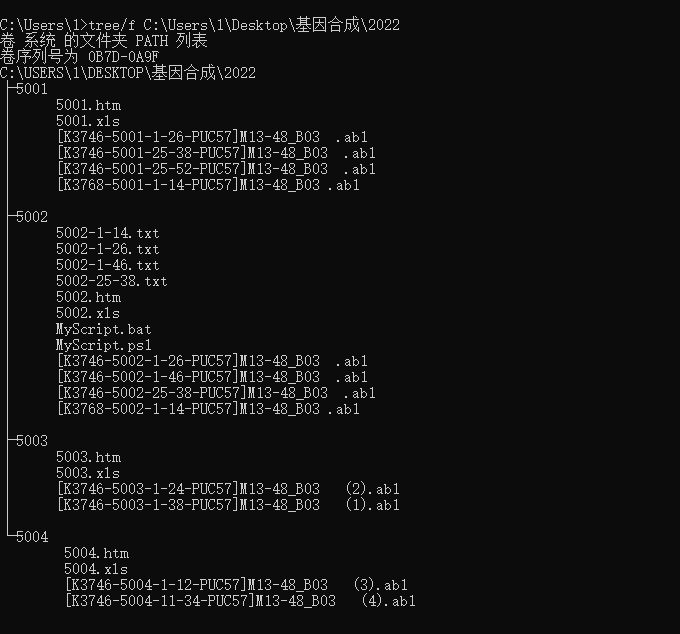
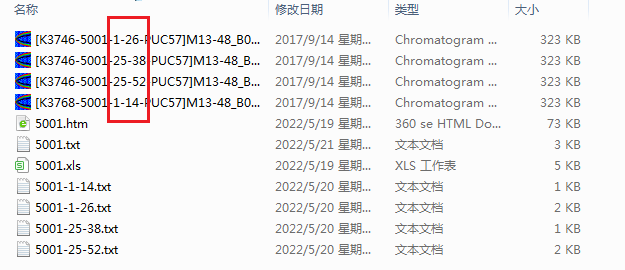
把27楼代码保存为MyScript.ps1: | $html = gc '.\5001.htm' -Raw -Encoding UTF8; | | | | $oligos_arr=[regex]::Matches($html, '(?i)(?<=<tr><td>oligos.*?style.*?>)[^<]+').value.Foreach{ | | ($_.Trim('|') -replace ' |[@\(+\)]' -split '\|').Foreach{ | | $e=$_.split(':'); | | @{ID=$e[0].Trim('-'); begin=[int]$e[1]; end=[int]$e[2]; } | | } | | } | | | | $_5gt3=[regex]::Match($html, "(?<=5'-->3'.*?style.*?>).*?(?=</td>)").value -replace '<.*?>'; | | | | | | | | ('5001-1-14','5001-1-26','5001-25-38','5001-25-52').ForEach{ | | $arr=$_.split('-'); | | $index1=$oligos_arr.ID.IndexOf($arr[0]+'_'+$arr[1]); | | $index2=$oligos_arr.ID.IndexOf($arr[0]+'_'+$arr[2]); | | | | if($index1 -ne -1 -and $index2 -ne -1){ | | [int]$t1=$oligos_arr[$index1].begin - 1; | | [int]$t2=$oligos_arr[$index2].end - 1; | | sc ".\$_.txt" -Value (-join($_5gt3[$t1..$t2])) -Force -Verbose -NoNewline; | | } | | } | | | | [Console]::Write("全部完成!");COPY |
同目录下放一个MyScript.bat: | @echo off | | PowerShell.exe -ExecutionPolicy Bypass -Command "& '%~dpn0.ps1'" | | exitCOPY |
直接执行MyScript.bat即可实现自动提取数据,虽然不懂Powershell功能,但是感觉比批处理还是要功能更强大一些。
 | 

 发表于 2022-5-24 10:20
|
发表于 2022-5-24 10:20
| 







 [/url
[/url