
标题: [文件操作] 批处理根据a文件夹里文件名两个位置之间的字符,剪切到b文件夹相同字符的子文件夹 [打印本页]
作者: 13545876873 时间: 2022-5-20 10:10 标题: 批处理根据a文件夹里文件名两个位置之间的字符,剪切到b文件夹相同字符的子文件夹
根据a文件夹里文件名两个位置之间的字符,把文件剪切到b文件夹相同字符的子文件夹里啊
我的D盘里有两个文件夹:基因合成和测序结果;
测序结果文件夹里有很多文件,比如:[K3746-5001-1-26-PUC57]M13-48_B03 ; [K3746-5001-25-48-PUC57]M13-48_B03;
[T4567-5003-25-48-PUC57]M13-47_C03 ; [V2001-5002-25-48-PUC57]M13-47_C03
基因合成文件夹里有子文件夹,子文件夹里又有文件夹5001 5002 5003 5004等等。
我想把测序结果文件夹里的文件,根据名字的第8-11个字符,分别是: 5001 5001 5003 5002,把相应的文件剪切到基因合成子 子相应文件夹里。
求大神教我啊 :'( :'( :'(
:'( :'( :'(
作者: 13545876873 时间: 2022-5-20 10:15
测序结果文件夹里的文件格式是ab1 :[K3746-5001-25-48-PUC57]M13-47_C03.ab1
作者: qixiaobin0715 时间: 2022-5-20 10:22
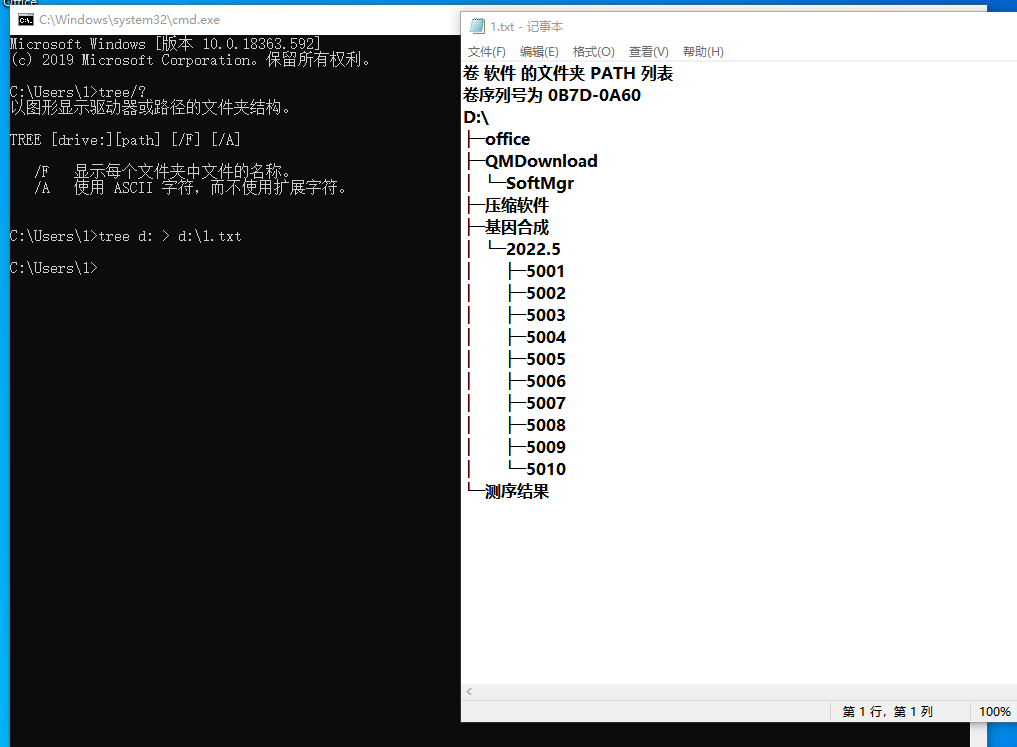
最好提供一下基因合成文件夹的结构:tree一下发上来。
作者: Batcher 时间: 2022-5-20 11:30
回复 4# 13545876873
推荐使用 tree 或 tree /f 命令说明你的文件夹结构,参考教程:
http://bbs.bathome.net/thread-2514-1-1.html
Q-07:怎样把CMD窗口里的结果复制出来?
http://bbs.bathome.net/thread-3473-1-1.html
如果需要上传截图,可以找个图床,例如:
http://bbs.bathome.net/thread-60985-1-1.html
作者: 13545876873 时间: 2022-5-20 13:07
作者: qixiaobin0715 时间: 2022-5-20 13:43
回复 10# 13545876873
将下面代码保存为ANSI编码:- @echo off
- cd /d "D:\基因合成\2022.5\"
- for /d %%i in (*) do (
- move "D:\测序结果\*-%%i-*.ab1" "%%i\"
- )
- pause
作者: yakeyun 时间: 2022-5-20 13:55
本帖最后由 yakeyun 于 2022-5-20 14:07 编辑
回复 1# 13545876873
贴主要表达的意思:
D盘存在如下两个目录:
D:\基因合成\2022.5
\5001\
\5002\
\5003\
D:\测序结果
\[K3746-5001-1-26-PUC57]M13-48_B03.ab1
\[K3746-5001-25-48-PUC57]M13-48_B03.ab1
\[T4567-5003-25-48-PUC57]M13-47_C03.ab1
\[V2001-5002-25-48-PUC57]M13-47_C03.ab1
需求读取D:\测序结果目录中的文件,根据5001、5002、5003字段分类文件,然后移动到D:\基因合成\2022.5\目录下对应字段文件夹中。
另存为ANSI格式,不然中文目录不会被识别。- @echo off&setlocal enabledelayedexpansion
- for /f %%a in ('dir /a /s /b "D:\测序结果\*.ab1"') do (
- set dvn=%%a
- for /f "tokens=2 delims=[]" %%b in ("!dvn!") do (
- for /f "tokens=2 delims=-" %%c in ("%%b") do (
- set mls=%%c
- set Ns=%date:~0,4%
- set Ys=%date:~5,2%
- if !Ys!==01 (set "Ys=!Ys:01=1!")
- if !Ys!==02 (set "Ys=!Ys:02=2!")
- if !Ys!==03 (set "Ys=!Ys:03=3!")
- if !Ys!==04 (set "Ys=!Ys:04=4!")
- if !Ys!==05 (set "Ys=!Ys:05=5!")
- if !Ys!==06 (set "Ys=!Ys:06=6!")
- if !Ys!==07 (set "Ys=!Ys:07=7!")
- if !Ys!==08 (set "Ys=!Ys:08=8!")
- if !Ys!==09 (set "Ys=!Ys:09=9!")
- set "today=!Ns!.!Ys!"
- if exist D:\基因合成\!today!\!mls! (move /y "!dvn!" "D:\基因合成\!today!\!mls!" >nul) else (
- md "D:\基因合成\!today!"
- md "D:\基因合成\!today!\!mls!"
- move /y "!dvn!" "D:\基因合成\!today!\!mls!" >nul
- )
- )
- )
- )
- exit
作者: qixiaobin0715 时间: 2022-5-20 14:41
本帖最后由 qixiaobin0715 于 2022-5-20 14:42 编辑
回复 10# 13545876873
这样也行:- @echo off
- cd /d "D:\测序结果"
- for /f "tokens=1-2* delims=-" %%a in ('dir /b /a-d *.ab1') do (
- if not exist "D:\基因合成\2022.5\%%b" md "D:\基因合成\2022.5\%%b"
- move "%%a-%%b-%%c" "D:\基因合成\2022.5\%%b\"
- )
- pause
作者: 13545876873 时间: 2022-5-20 15:11
本帖最后由 13545876873 于 2024-10-28 16:42 编辑
谢谢大哥们的帮助,这个问题已经解决
我还有个问题: 比如在我把[G3005-5001-11-24-PUC57]M13-48_B03.ab1 剪切到5001文件夹里后。
5001文件夹里有一个htm文件 , 我要怎么把htm里 11-24的的序列提取出来,并新建一个5001-11-24的文本,把这个序列粘贴进去。 同时新建一个5001的文本,把5001全序列粘贴进去啊 :'(
:'(
作者: 13545876873 时间: 2022-5-20 15:48
回复 13# qixiaobin0715
大哥,这个运行很好
能教教我另外一个难题,怎么从HTM里提取相应的序列吗。 每天重复太多了 :'( :'(
作者: qixiaobin0715 时间: 2022-5-20 16:00
你把之前5001文件夹和处理后文件夹要达到的效果发到网盘上共享,我可以试试看。
作者: yakeyun 时间: 2022-5-20 17:06
回复 15# 13545876873
条件本身就冲突,没办法操作。5001存在2个文档,取值会出错。
作者: 13545876873 时间: 2022-5-20 19:06
:'( :'( 回复 18# yakeyun
作者: xczxczxcz 时间: 2022-5-21 07:21
传百度阿里糸估计很多人不会点。蓝奏才方便,123次之。
作者: 13545876873 时间: 2022-5-21 07:48
大哥 回复 17# qixiaobin0715
蓝奏链接 https://wwn.lanzoub.com/iV6li056n7cj
作者: qixiaobin0715 时间: 2022-5-21 09:55
没看太明白:
1.1-14、1-26、25-38、25-52是如何对应的;
2.用记事本打开htm文件后,你所说的序列行有何特点,如何就确定这行就是你所要的。
作者: 13545876873 时间: 2022-5-21 10:36
回复 26# qixiaobin0715
htm文件不是用记事本打开哈,就用网页打开。
作者: 13545876873 时间: 2022-5-21 10:37
回复 26# qixiaobin0715
作者: 13545876873 时间: 2022-5-21 11:00
回复 26# qixiaobin0715

作者: 13545876873 时间: 2022-5-21 11:09
回复 26# qixiaobin0715
比如
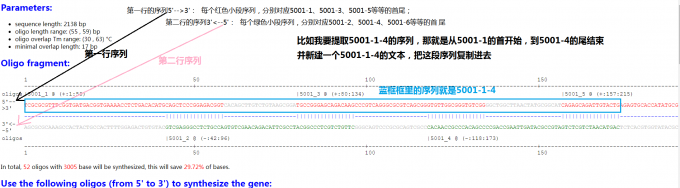
5001-1-14就是第一行:第1个字母到 第572个的全部 字母; 在把文件从测序结果剪切到相应文件夹之后,同时新建一个5001-1-14的文本,并把这段字母复制进去
5001-1-26就是第一行:第1个字母到 第1064个的全部 字母; 在把文件从测序结果剪切到相应文件夹之后,同时新建一个5001-1-26的文本,并把这段字母复制进去
5001-25-38就是第一行:第972个字母到 第1550个的全部 字母; 在把文件从测序结果剪切到相应文件夹之后,同时新建一个5001-25-38的文本,并把这段字母复制进去
5001-25-52就是第一行:第972个字母到 第2138个的全部 字母 在把文件从测序结果剪切到相应文件夹之后,同时新建一个5001-25-52的文本,并把这段字母复制进去
5001就是第一行:第1个字母到 第2138个的全部 字母 ; 最后同时新建一个5001的文本,把第一行全部字母复制进去
作者: yakeyun 时间: 2022-5-22 18:02
回复 22# 13545876873
代码备份留存,如果单纯的只需要提取11~24行信息,可以用下面的代码,但是你的文件没有规律,且文件用记事本打开一行的内容太长了,最主要的是要你自己明白这个文件和其它文件是否有规律,比如字符位置是否固定等等。- @echo off&setlocal enabledelayedexpansion
- set today=2022.5
- set mls=5001
- set txts=5001-11-24
- for /f %%d in ('dir /a /s /b "D:\基因合成\!today!\!mls!\*.htm"') do (
- for /f "skip=10 tokens=*" %%e in (%%d) do (
- set op=%%e
- set /a m+=1
- if !m! LEQ 14 (
- echo !op!
- )
- )
- ) >D:\基因合成\!today!\!mls!\!txts!.txt
- (
- for /f %%i in ('type D:\基因合成\!today!\!mls!\!txts!.txt') do (
- echo %%i
- )
- )>D:\基因合成\!today!\!mls!\!mls!.txt
- exit
作者: 13545876873 时间: 2022-5-22 18:23
大哥 回复 23# yakeyun
你的这个5001-11-24我运行出来是这样的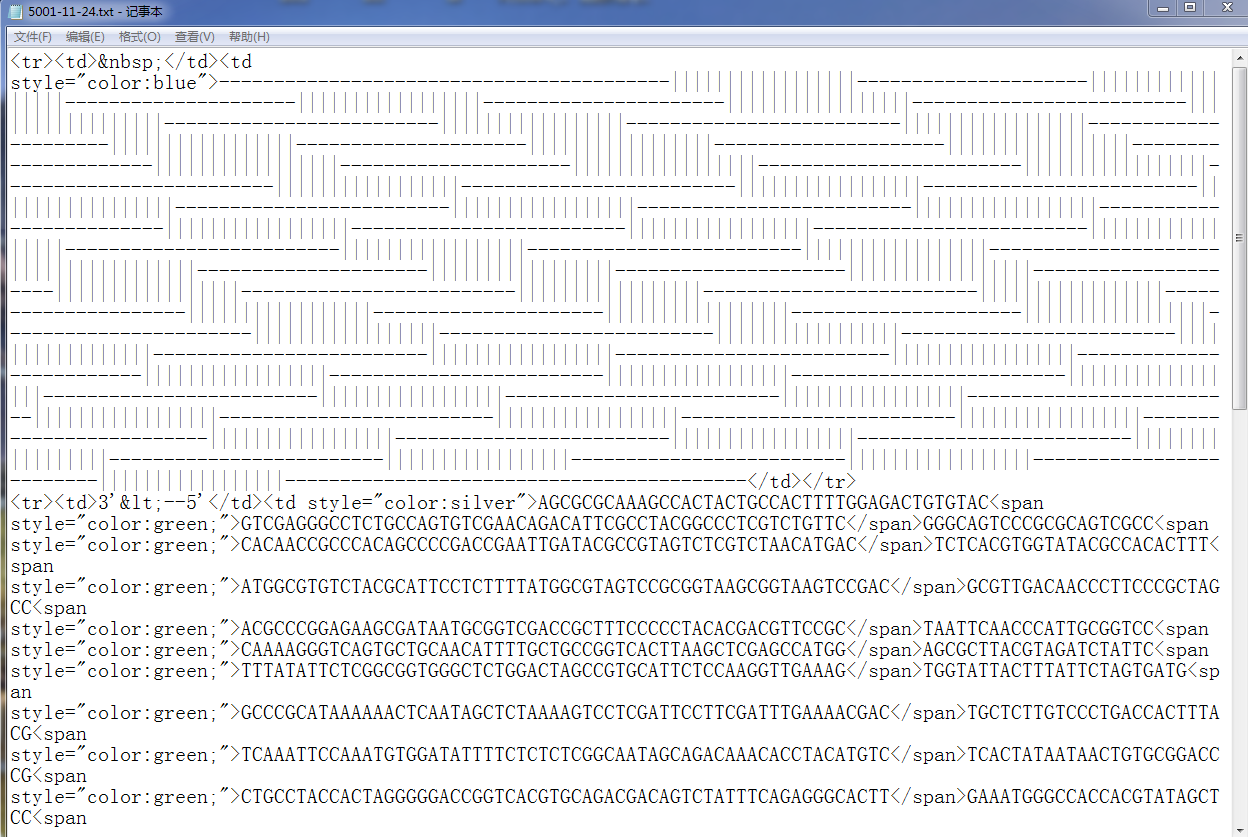
不是我想要的结果哈 ;
比如5001-11-24,我想要的是5001-11(397:451)的首(第397个字母),
到5001-24(934:988)的尾(第988个字母),之间的所有字母(文档里只要这些字母,其他的字母符号都不要)
这个是根据从测序结果文件夹里,剪切到基因合成文件夹里的ab1格式文件,的名字来选的哈(红框框处)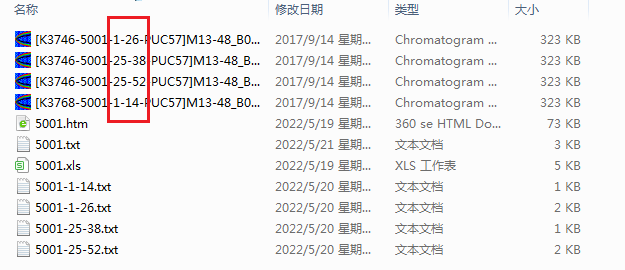
我想要所有从测序结果文件夹里,剪切到基因合成文件夹里的ab1格式文件,都会根据名字上的红框框处,自动生成一个txt文档(并把这两个数字之间的字母复制进去)
作者: yakeyun 时间: 2022-5-22 22:16
本帖最后由 yakeyun 于 2022-5-22 23:26 编辑
回复 24# 13545876873
你这个获取的结果已经很明显了,说明html文件并不是TXT文件里面的行内容,需要你自己找一下规律,然后根据规律来截取。
比如第十行有数据,那么第十行的第几个到第几个是固定字符,或者字符被特殊字符夹在中间等。只有有规律的文本才能被批处理。
比如我帮你找出来的规律,你的5001.txt序列文件,可以用我上面发的代码获取到,不过代码要改成下面这个。
从取值可以看到,所有类容都是一行显示,为了发现规律,我故意将前面“><span”后面的字符分行。那么剩下的规律就是将取值进行赋值,
比如获取到的“5001-11-24.txt”文本,除了文件头和文件尾没有规律,中间部分全部都是规律字符,只需要将结果做4次替换,就可以取到正确结果。- @echo off&setlocal enabledelayedexpansion
- set txts=5001-11-24
- for /f %%d in ('dir /a /s /b ".\*.htm"') do (
- for /f "skip=9 tokens=*" %%e in (%%d) do (
- set op=%%e
- set /a m+=1
- if !m! LEQ 1 (
- echo !op!
- )
- )
- ) >.\!txts!.txt

通过替换法测试发现,提取后的文本,只需要再次替换下面4处文本即可:
<tr><td>5'-->3'</td><td style="color:silver">
<span style="color:red;">
</span>
</td></tr>
作者: 13545876873 时间: 2022-5-23 08:16
回复 25# yakeyun
大哥,htm的规律是这样的哈: 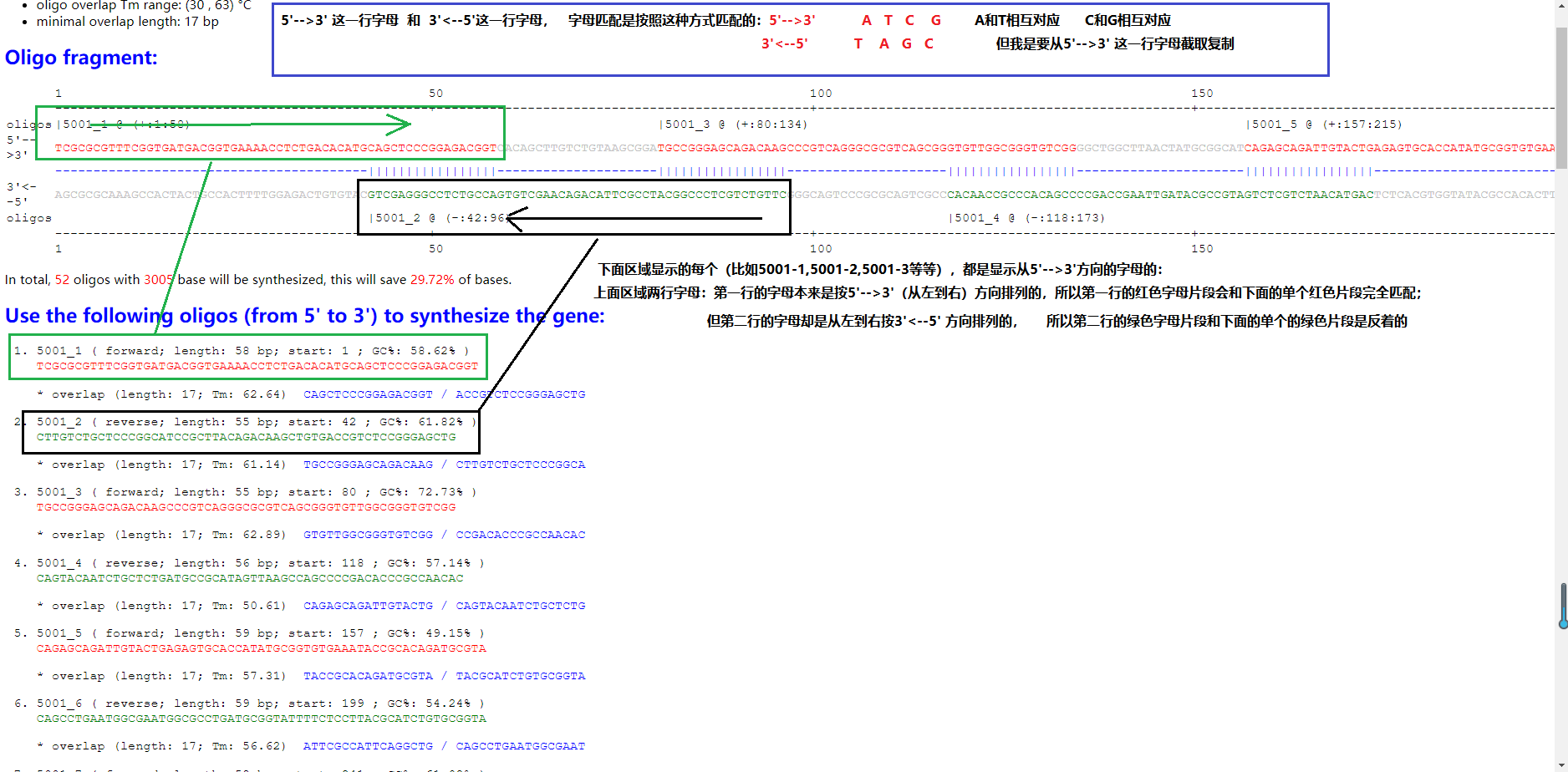
作者: xczxczxcz 时间: 2022-5-23 10:12
给你一个WIN10的吧,至少PS>4.0
要保存哪些文件自行按格式修改, 脚本保存为 xxx.ps1- $html = gc '.\5001.htm' -Raw -Encoding UTF8;
-
- $oligos_arr=[regex]::Matches($html, '(?i)(?<=<tr><td>oligos.*?style.*?>)[^<]+').value.Foreach{
- ($_.Trim('|') -replace ' |[@\(+\)]' -split '\|').Foreach{
- $e=$_.split(':');
- @{ID=$e[0].Trim('-'); begin=[int]$e[1]; end=[int]$e[2]; }
- }
- }
-
- $_5gt3=[regex]::Match($html, "(?<=5'-->3'.*?style.*?>).*?(?=</td>)").value -replace '<.*?>';
- #$_3lt5=[regex]::Match($html, "(?<=3'<--5'.*?style.*?>).*?(?=</td>)").value -replace '<.*?>';
-
- <# 5000-1-14 ... #>
- ('5001-1-14','5001-1-26','5001-25-38','5001-25-52').ForEach{
- $arr=$_.split('-');
- $index1=$oligos_arr.ID.IndexOf($arr[0]+'_'+$arr[1]);
- $index2=$oligos_arr.ID.IndexOf($arr[0]+'_'+$arr[2]);
-
- if($index1 -ne -1 -and $index2 -ne -1){
- [int]$t1=$oligos_arr[$index1].begin - 1;
- [int]$t2=$oligos_arr[$index2].end - 1;
- sc ".\$_.log" -Value (-join($_5gt3[$t1..$t2])) -Force -Verbose -NoNewline;
- }
- }
-
- [Console]::Write("全部完成 按任意键退出");
- [void][Console]::ReadKey();
作者: qixiaobin0715 时间: 2022-5-23 14:36
回复 22# 13545876873
你先看一下6楼代码能完成先前的需求吗?
作者: 13545876873 时间: 2022-5-23 15:56
回复 25# yakeyun
大哥,你的意思是这样的吧
但这不是我想要的呀
你这个方法最后把<tr><td>5'-->3'</td><td style="color:silver">这些字符删除后,文本里就是5001的全部的2138个字母;然后我再去手动查找截取,,,那也可以直接再htm文件里复制粘贴到txt里了啊:'(
<span style="color:red;">
</span>
</td></tr>
我想要的是能不能:我测序结果文件夹里有很多ab1文件:[K3746-5001-1-26-PUC57]M13-48_B03 ; [K3746-5001-25-48-PUC57]M13-48_B03;
[T4567-5003-25-48-PUC57]M13-47_C03 ; [V2001-5002-25-48-PUC57]M13-47_C03 等等
第一步: 在我用一个bat把这些ab1文件剪切到相应的基因合成文件夹5001,5001,5003,5002等等里后,每个文件夹里已经有一个相应的htm文件:5001.htm,5001.htm,5003.htm,5002.htm等等
第二步:在这些ab1文件被剪切进去后,相应的文件夹根据下面图片红框框处,自动生成一个txt文档(并把这两个数字之间的字母复制进去)[url=https://imgtu.com/i/XpY3bd]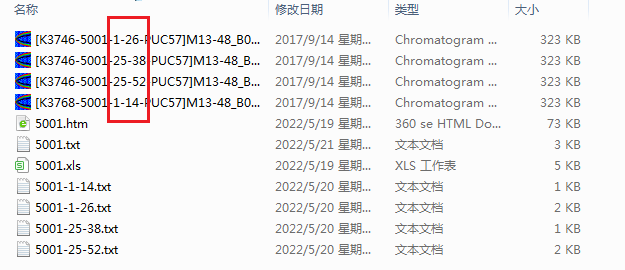 [/url
[/url
:'( :'( :'(
作者: 13545876873 时间: 2022-5-23 16:01
回复 27# xczxczxcz
大哥,你这个要保存什么,的自己修改,那我有很多文件夹:5002,5003。。。。5100 那和直接在htm上复制粘贴没啥区别了呀 :'(
作者: yakeyun 时间: 2022-5-23 21:35
本帖最后由 yakeyun 于 2022-5-23 21:40 编辑
回复 30# 13545876873
把27楼代码保存为MyScript.ps1:- $html = gc '.\5001.htm' -Raw -Encoding UTF8;
-
- $oligos_arr=[regex]::Matches($html, '(?i)(?<=<tr><td>oligos.*?style.*?>)[^<]+').value.Foreach{
- ($_.Trim('|') -replace ' |[@\(+\)]' -split '\|').Foreach{
- $e=$_.split(':');
- @{ID=$e[0].Trim('-'); begin=[int]$e[1]; end=[int]$e[2]; }
- }
- }
-
- $_5gt3=[regex]::Match($html, "(?<=5'-->3'.*?style.*?>).*?(?=</td>)").value -replace '<.*?>';
- #$_3lt5=[regex]::Match($html, "(?<=3'<--5'.*?style.*?>).*?(?=</td>)").value -replace '<.*?>';
-
- <# 5000-1-14 ... #>
- ('5001-1-14','5001-1-26','5001-25-38','5001-25-52').ForEach{
- $arr=$_.split('-');
- $index1=$oligos_arr.ID.IndexOf($arr[0]+'_'+$arr[1]);
- $index2=$oligos_arr.ID.IndexOf($arr[0]+'_'+$arr[2]);
-
- if($index1 -ne -1 -and $index2 -ne -1){
- [int]$t1=$oligos_arr[$index1].begin - 1;
- [int]$t2=$oligos_arr[$index2].end - 1;
- sc ".\$_.txt" -Value (-join($_5gt3[$t1..$t2])) -Force -Verbose -NoNewline;
- }
- }
-
- [Console]::Write("全部完成!");
同目录下放一个MyScript.bat:- @echo off
- PowerShell.exe -ExecutionPolicy Bypass -Command "& '%~dpn0.ps1'"
- exit
直接执行MyScript.bat即可实现自动提取数据,虽然不懂Powershell功能,但是感觉比批处理还是要功能更强大一些。
作者: 13545876873 时间: 2022-5-24 08:19
回复 27# xczxczxcz
大哥用你和 31楼大哥的方法,我在其他的文件夹里也试过了,运行没有问题
能不能在文件夹(2022)外面搞一个bat,这个bat可以把这个文件夹(2022) 里的所有子文件夹(5001,5002,5003,5004等等),
按照文件夹里的ab1文件上的区间,把所有文件夹都生成相信的txt文档啊
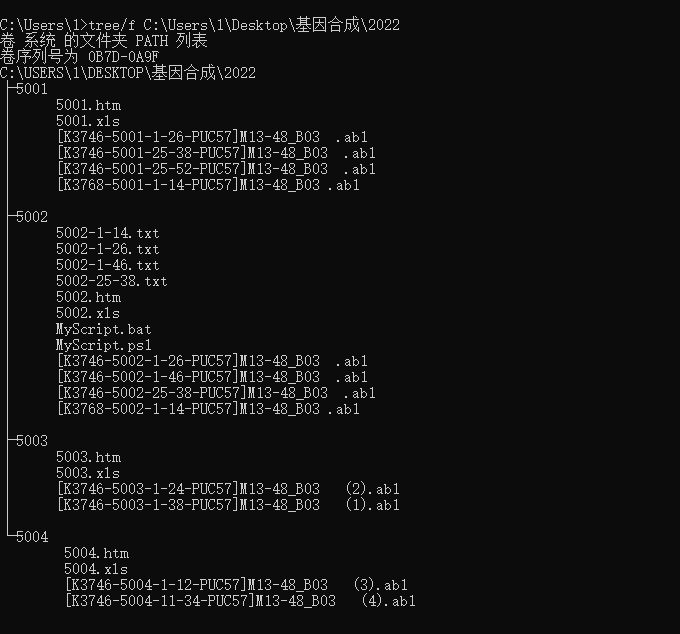
作者: 13545876873 时间: 2022-5-24 08:20
回复 31# yakeyun
大哥这个运行得没问题哈
作者: 13545876873 时间: 2022-5-24 08:26
回复 28# qixiaobin0715
大哥 用了xczxczxcz 和31楼大哥的方法,可以在每个子文件夹里,在MyScript.ps1 文档里修改 ,然后用MyScript.bat 自动生成了哈
我在想能不能在搞一个bat,不用修改MyScript.ps1 文档,也可以批量处理多个子文件夹啊
作者: qixiaobin0715 时间: 2022-5-24 09:05
问你6楼代码测试结果就是为了继续下一步,你也不说一声。假设6楼代码没有问题,试试下面代码是否可行。未测试,效率可能不高:- @echo off
- cd /d "D:\基因合成\2022.5\"
- for /d %%i in (*) do (
- move "D:\测序结果\*-%%i-*.ab1" "%%i\"
- )
- for /d %%i in (*) do (
- pushd "%%i"
- for /f "tokens=2-4 delims=-" %%a in ('dir /b /a-d *.ab1') do (
- set n=0
- setlocal enabledelayedexpansion
- for /f "delims=" %%j in ('findstr ">" %%a.htm') do (
- set "str1=%%j"
- set "str1=!str1:*span =<span !"
- set "str1=!str1:</td></tr>=! span"
- set "str1=!str1:<= !"
- set "str1=!str1:>= !"
- set "str1=!str1:/=!"
- for %%k in (!str1!) do (
- if "%%k"=="span" (
- if !n! geq %%b if !n! leq %%c set str2=!str2!!var!
- set /a n+=1
- )
- set "var=%%k"
- )
- )
- echo,!str2!>%%a-%%b-%%c.txt
- endlocal
- )
- popd
- )
- pause
作者: 13545876873 时间: 2022-5-24 10:20
回复 36# qixiaobin0715
大哥
你这个可以把ab1文件,从测序结果文件夹里,剪切到相应文件夹;
也能在相应文件夹里生成相应的txt文档,但就是有一个小小的问题,我用图片说明一下哈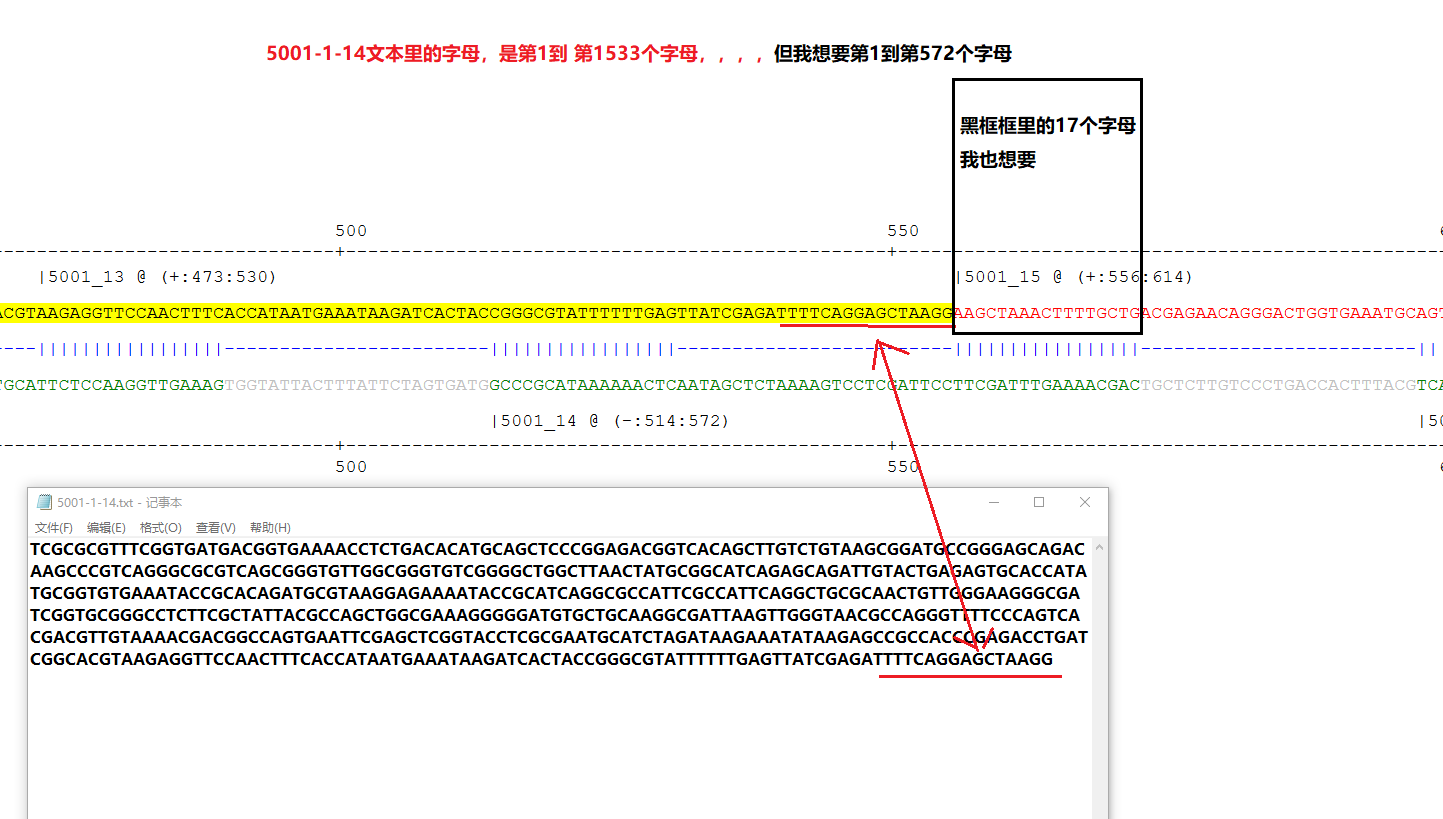

比如: 5001-25-52这个文本里显示的字母完全是我想要(第52个也就是到了最后一个字母)
但 5001-1-14文本里的字母 不是到5001-14的最后一个字母,它少了17个字母
5001-1-26文本里的字母 不是到5001-26的最后一个字母,它少了17个字母
5001-25-38文本里的字母 不是到5001-38的最后一个字母,它少了17个字母
只有要选取到最后的(5001-52)字母,才会完全正确,,,但如果选取到中间就结束,就会少17个字母啊:'(
作者: qixiaobin0715 时间: 2022-5-24 10:41
回复 37# 13545876873
也不知你这是什么规则,文本规律和你的需求差距较大,还是你自己好好整理思路,看看文本和你的需求到底有何联系。htm文件要用记事本而不能用ie打开,因为处理的是htm的源代码而不是用ie打开后的效果。
作者: xczxczxcz 时间: 2022-5-24 14:03
回复 35# 13545876873
基本上是,俺灰常不喜欢WIN7那个垃圾阉割系统,所写就不想兼容它。
作者: xczxczxcz 时间: 2022-5-24 14:08
回复 32# 13545876873
SO EASY , 但有点懒, 你自己附件不一次全部提供,偶只是照附件内容写写。
作者: 13545876873 时间: 2022-5-24 14:32
回复 38# qixiaobin0715
好吧
谢谢大哥哈
作者: 13545876873 时间: 2022-5-24 14:32
回复 39# xczxczxcz

作者: qixiaobin0715 时间: 2022-5-25 10:52
回复 37# 13545876873
我想你要的结果可能是除了正常分组序列的字符之外,还要将序列向右偏移17个字符,看看这样是否符合你的需求,未经测试:- @echo off
- cd /d "D:\基因合成\2022.5\"
- for /d %%i in (*) do (
- move "D:\测序结果\*-%%i-*.ab1" "%%i\"
- )
- for /d %%i in (*) do (
- pushd "%%i"
- set x=0
- setlocal enabledelayedexpansion
- for /f "delims=" %%j in ('findstr ">" %%i.htm') do (
- set "str1=%%j"
- set "str1=!str1:"color:red;">= ### !"
- set "str1=!str1:</span>= ### !"
- set "str1=!str1:<= !"
- for %%l in (!str1!) do (
- if "!str2!" == "###" (
- set /a x+=1
- set _!x!=%%l
- )
- set str2=%%l
- )
- )
- for /f "tokens=2-4 delims=-" %%a in ('dir /b /a-d *.ab1') do (
- setlocal enabledelayedexpansion
- for /l %%d in (%%b,1,%%c) do (
- set var=!var!!_%%d!
- )
- set /a n=%%c+1
- if defined _!n! (
- for %%e in (_!n!) do (
- echo,!var!!%%e:~,17!>%%a-%%b-%%c.txt
- )
- ) else (
- echo,!var!>%%a-%%b-%%c.txt
- )
- endlocal
- )
- endlocal
- popd
- )
- pause
作者: 13545876873 时间: 2022-5-25 12:26
回复 43# qixiaobin0715
大哥,这个可以把ab1文件 剪切到相应文件夹,也能生成相应的txt文档,但txt文档是空的哈,里面一个字母都没有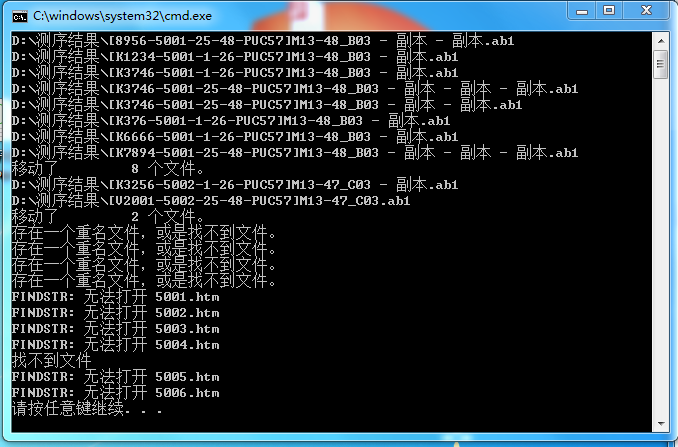
cmd显示 无法打开htm文件
作者: qixiaobin0715 时间: 2022-5-25 12:46
本帖最后由 qixiaobin0715 于 2022-5-25 13:25 编辑
你的测试文件有问题:
1.文件夹中存在序列相同的文件。比如5001文件夹中存在文件名片段相同的字符,5001-25-48字段和5001-1-26字段各重复4个。
2.你提供的测试文件中htm文件的文件名是和文件夹名相同的,我猜想这次测试应当是不同的。比如文件夹5001中的htm文件应当是5001.htm。
3.如果htm文件名有空格请把代码第10行中的 %%i.htm 用双引号(注意是英文引号)括起来 "%%i.htm"。
你可以用你提供的 测试文件试一下。
或者你用37楼测试成功的测试文件试试。
先前没有测试,刚刚用你提供的文件测试没有发现问题。
要么就是htm文件的编码问题。
此帖不再关注
作者: 13545876873 时间: 2022-5-25 13:14
回复 45# qixiaobin0715
大哥 好奇怪啊 , 我用我上传的5001文件夹和文件处理,确实没有问题。
, 我用我上传的5001文件夹和文件处理,确实没有问题。
但其他的文件夹里,生成的txt文本都是空白, 好奇怪啊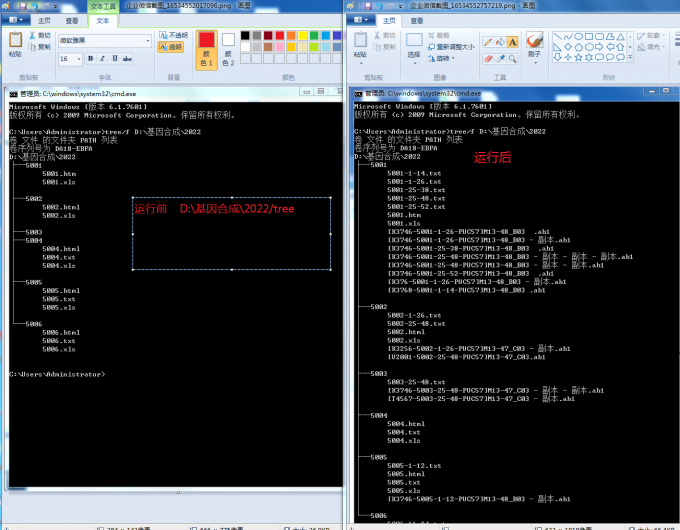
作者: 13545876873 时间: 2022-5-25 13:23
回复 44# qixiaobin0715
大哥 我上传了5001-5004,帮忙看看问题出在哪呢
蓝奏: https://wwn.lanzoub.com/icTLd05erpcj
作者: qixiaobin0715 时间: 2022-5-25 13:36
回复 44# 13545876873
将代码第10行 %%i.htm 改为 %%i.html
然后将代码另存为ANSI编码。
作者: 13545876873 时间: 2022-5-25 13:52
回复 45# qixiaobin0715
大哥 可以啦,完全没问题啦
非常感谢大哥和其他几位大哥的帮助:lol
作者: qixiaobin0715 时间: 2022-5-25 15:42
本帖最后由 qixiaobin0715 于 2022-5-25 15:46 编辑
回复 46# 13545876873
记得你还需要提取一个全序列文本。
可以在第40楼代码中,原第18~19行之间增加一行:复制代码
原第21~22行之间增加一行:复制代码
就OK了!
记得要将代码另存为ANSI编码啊。
作者: 13545876873 时间: 2022-5-26 11:34
回复 47# qixiaobin0715
好的,谢谢大哥哈
| 欢迎光临 批处理之家 (http://www.bathome.net/) |
Powered by Discuz! 7.2 |